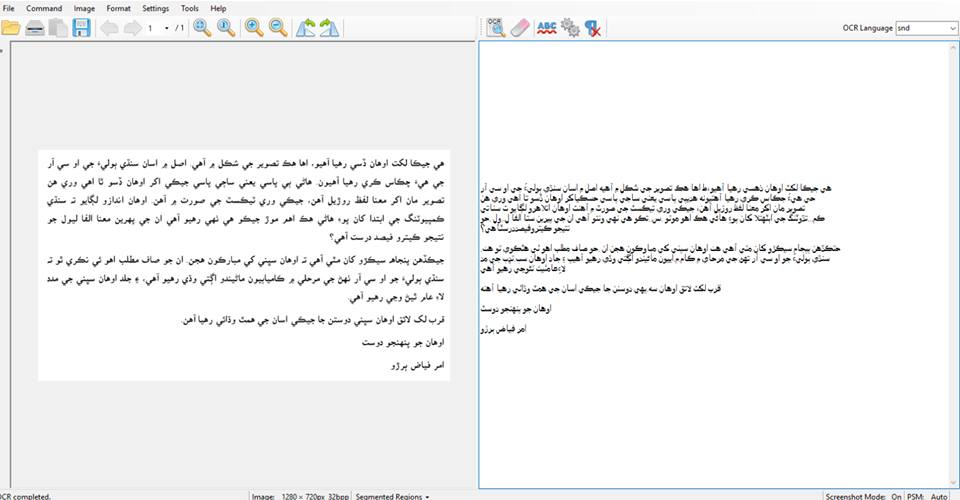
سنڌي ٻوليءَ جو اکر شناس/OCR
شبير ڪنڀار
سنڌي او سي آر _ سنڌي ٻوليءَ جي ٽيڪنالاجيءَ ۾ اچڻ واري 1987ع واري ايجاد کانپوءِ ٻي وڏي وِک آھي، او سي آر OCR (Optical Character Recognition) يعني تصويرن مان اکرن/لکت کي سڃاڻندڙ سافٽويئر، هيءُ اهڙو سافٽويئر آهي، جيڪو ھٿرادو ذھانت (Artificial Intelligence) تحت اڳ ۾سيکاريل ھوشياريءَ جي بنياد تي، ڪنھن ڪمپيوٽر/ ڪمپيوٽنگ ڊوائس ۾ ايتري تہ چالاڪي پئدا ڪري ٿو، جو اھو ڪمپيوٽر/ ڊوائس ڪنھن ڪئميرا مان نڪتل يا اسڪين ڪيل تصوير (Image) ۾ موجود لکيل اکري مواد کي سڃاڻي وٺندو آھي ۽ ڪتب آيل اکرن کي، تصوير مان روڙي، ھڪ لمحي ۾ پنھنجي ڊيٽابيس ۾ موجود معلومات سان ڀيٽي، بيھڪ جي نشانين سميت، واپس ھوبھو شڪل ۾ ڪمپوز ڪيل مواد ۾ مٽائي ڇڏيندو آھي، جنھن کي ڪاپي، پيسٽ ڪري يعني ٻيھر استعمال ڪري سگهبو آھي.
دنيا ۾ OCR جي مدد سان سياح روڊن تي لڳل بورڊن تي لکيل معلومات کي اکرن ۾ تبديل ڪري انھن کي ترجمو ڪري مطلب حاصل ڪرڻ لڳا آھن ۽ گهربل اکرن کي گوگل وسيلي سرچ/ڳولها لاءِ پڻ استعمال ڪرڻ عام ٿي ويو آھي. ڪنھن بہ ٻوليءَ جي مڪمل OCR ٺھڻ کانپوءِ لکيل مواد يا ڪتابن کي ڪمپوز ڪرڻ جي ضرورت ئي نہ رهندي آهي، پر گهربل ڪتاب کي اسڪين ڪري انجي تصويري عڪس/ Image کي هڪڙي ڪلڪ سان واپس ڪمپوز ٿيل ٽيڪسٽ ۾ مٽايو ويندو آھي، تنھنڪري ٻيھر ڪمپوز ڪرڻ کان، هي عمل تمام گهڻو بھتر آهي، ڇاڪاڻ تہ پروف ريڊنگ فني سٽاءُ وغيرہ ڪمپوزنگ جا وڏا مسئلا آهن، OCR ۾ خودڪار نظام تحت درست ٿي ويندا آهن. OCRجي مدد سان ئي دنيا جون وڏيون لائبرريون پنھنجي ڪتابن جا E-Book ايڊيشن پڌرا ڪرڻ ۾ ڪامياب ٿيون آهن. دنيا جي وڏي برٽش لئبريري پنھنجا ساڍا چوئيتاليھ لک ڪتاب 2017ع تائين ’گوگل بُڪس‘ ۽ ’گُڊ ريڊس‘ جي ڀائيواريءَ سان آن لائين ڪرڻ جي جيڪا رٿا جوڙي آهي، سا پڻ ڪتابن جي ٻيھر ڪمپوزنگ سان نہ پر OCR جي ڪري ئي ممڪن ٿي آهي.
سنڌي ٻوليءَ جي او سي آر OCR (Optical Character Recognition) تي ڪيترن ئي ماڻھن/ شاگردن مختلف جڳھين ۽ ڏيھي توڙي پرڏيھي مادر علمين ۾ عام طور/ پڙھڻ دؤران تمام گهڻيون ڪوششون ڪيون، ٻنھي صورتن، انفرادي توڙي يونيورسٽين جي سطح تي، او سي آر جي پروگرامنگ ڪئي وئي، پر اهو سڄو پورھيو فقط تحقيقي حدن تائين رهيو ۽ ان جو ڪو ڪنڪريٽ نتيجو نہ نڪري سگھيو. اڄ بہ اھڙا ’رٿائي رسرچ پيپرن جا نمونا‘ گوگلنگ وسيلي ڏسي سگهجن ٿا.
اھو چڱيءَ ريت ظاهر آهي تہ ڪنھن بہ ٻوليءَ جي OCR جھڙي ورچائيندڙ ۽ ٿڪائيندڙ پورھئي لاءِ ٻوليءَ سان عشق جي حد تائين پيار ڪندڙ تمام ذھين، اڻٿڪ ۽ برجستن ماڻھن تي مشتمل هڪ مضبوط ٽيم جي ضرورت ٿيندي آهي. اھڙي ٽيم جنھن ۾ ڪم ڪندڙ، پروگرامنگ جي پاسي کان تہ ڀڙ هجن ئي ھجن پر کين، ٻوليءَ جي استعمال ۽ ان جي تاڃي پيٽي جي ڀليءَ ڀت پروڙ پوندي هجي. سنڌي ٻوليءَ جي اها خوشنصيبي هئي جو ھڪ ئي وقت سنڌي ٻوليءَ جي تاڃي پيٽي/ گهاڙيٽي ۽ ڪمپيوٽر پروگرامنگ تي عبور رکندڙ، خيرپور ڄائي پياري امر فياض ٻرڙي (سنڌي ٻولي اٿارٽيءَ جي ڪمپيوٽر سيڪشن جو انچارج) ۽ سندس شاگردياڻي پنجاب جي شھرخوشاب جي ڄائي محترمہ صائمہ اصغر (مائڪروسافٽ وزيوئل اسٽوڊيو ۽ ڪور پروگرامنگ جي لائسنز يافتہ ڊولپر، سائوٿ ايشين ٻولين جي انجنيئرنگ جي ڪوڊيڪس ڊولپر) گڏجي ھن چئلينجنگ رٿا کي جون 2015ع تي هٿ ۾ کڻڻ جي ھمٿ ڪئي.
ھن کان پھرين OCR تي شروع ڪيل رٿائون، جيئن تہ ڪا ڪاميابي ماڻي نہ سگهيون ھيون، انڪري ھن رٿا ۾ ھٿ وجهڻ ڪو ھمٿائيندڙ فيصلو نہ ھو، پر ھڪ وڏو چئلينج ھو جنھن جي ڪاميابيءَ جو بنياد درست رٿابنديءَ ۽ مستقل مزاجيءَ تي مشتمل ھو، ڇاڪاڻ تہ ھيءَ ھڪ ڊگهي رٿا ھئي ۽ ٻيو تہ OCR تي ٿيل ڪمن ۾ ماڻھن جي ناڪامي بہ ڪو سٺو مثال نہ ھئي، تنھنڪري سڀني مثالن کي سامھون رکندي رٿا جي ڪمن جي ونڊ ورھاست کي ھيٺيئن طرح پاڻ ۾ ورھايو ويو:
- ٻوليءَ لاءِ بنيادي پروگرامنگ، جنھن ۾ ٽيسرايڪٽ وسيلي باڪس ايڊيٽنگ جو ڪم، اکرن جي ٽہ پاسائين (3D) ڊگرين جو ڪم، ٻوليءَ جي مختلف شڪلين ۽ نمونن جنهن ۾ منفرد جملا، گھڻو استعمال ۾ ايندڙ لفظ، ڊڪشنري، اعراب ۽ ٽٻڪا، انهن جا صرف او سي آر لاءِ تصوراتي ڪوڊ رکڻ، هر اکر جي مختلف شڪلين (ب بـ ـبـ ـب) اکرن جي لگيچرز (اللہ، ﷴ، لا) جي ٽريننگ ڏيڻ وغيرہ جھڙن انتھائي پيچيدہ ڪمن کي امر فياض ۽ صائمہ گڏجي پنھنجي ذمي کنيو.
- ٻوليءَ جي ڊيٽا کي گڏ ڪرڻ ۽ ڊڪشنريءَ ۾ ترتيب وغيرہ اھڙا ڪم آھن جيڪي انيس ڪاڪا ۽ فهد ميمڻ جي ڪيا ويا.
- فونٽ بابت ٽيڪنيڪل ڪم اکرن جو پاڻ ۾ ڳانڍاپو، لگيچرز جي بناوت ۽ ڪوڊنگ تي مشتمل سڀئي ڪم ۽ فونٽ جي سٽاءَ، بيھڪ، ٻوليءَ ۾ ان جي استعمال ۽ OCR واسطي اکري مسئلن بابت سڀئي ڪم مون (شبير ڪنڀار) جي ذمي ۾ ڪيا ويا.
جڏھن 2 تہ ٻارنھن ٿيندا آھين تہ پوءِ 5 تہ ... ڪيترا ٿيندا اھو پاڻ حساب لڳايو، 5 ماڻھن تي مشتمل ھن ٽيم پنھنجي ڪم ۾ ڪيترو نور نچويو ھوندو ان جو اندازو ھن مان لڳائي سگهجي ٿو تہ ھن ڪم ۾ ڪتب آڻڻ لاءِ اڻ ڳڻ مک فائل آھن جن کي ھڪ ٻئي سان جوڙي ھڪ سرشتو ٺاھڻ لاءِ ئي لڳ ڀڳ، ڏيڍ سئو ڊائنامڪ لائبريري لنڪن/ڳنڍڻن جا فائل جدا آهن، جيڪي ھنن فائلن جو ربط هڪٻئي سان ڳنڍيندي نتيجن ڪڍڻ لاءِ مددگار طور ڪم ڪري رهيا آهن. ھتي فائلن جو تعداد انڪري ڄاڻايو ويو آھي تہ جيئن ڪم جي پيچدگيءَ جو اندازو ٿي سگهي ۽ خبر پوي تہ ھي ڪيترو انگهيل پورھيو آھي. مثال طور ھن ڳالهہ مان کڻي سمجهو تہ رڳو ٽريننگ فائيل جي ئي ماهيت جو اندازو کڻي لڳائجي، تہ ھينئن سولائيءَ سان سمجهي سگهجي ٿو تہ جيڪڏهن اهو ساڳيو فائل ورڊ ڊاڪيومينٽ ڏانھن موڪلجي ٿو تہ ان جا هن مھل تائين 7867 صفحا ٿين ٿا. ٻين فائلن جو تہ ڪو ڪاٿو ئي ڪونہ ٿو لڳائي سگھجي.
جيئن تہ ڇاپي ڪمن ۾ Typeface/font اکري ڏيک بنيادي حيثيت رکي ٿو، اوھان ڏٺو ھوندو تہ ڇاپي ڪمن ۾ اکرن جي جدا جدا نمونن تي مشتمل ليک شامل ھوندا آھن، خاص ڪري اکرن جي ھيڊنگ ٿلھن اکرن ۾ ھوندي آھي ۽ ٻي سڄي لکت سنھن اکرن ۾ ٿيندي آھي، اھو تہ ٿيو ساڳئي فونٽ جو جدا جدا ڏيک پر اسان وٽ اکرن جا ڪيترائي نمونا موجود آھن جيڪي لکت جي اسٽائيل/ڏيک کي سھڻي بڻائڻ لاءِ ڪتب اچن ٿا، ھن وقت تائين سنڌيءَ جا لڳ ڀڳ 300 کان مٿي فونٽ جاري ٿي چڪا آھن جيڪي مختلف ويبسائيٽن تي مفت موجود آھن. جن مان اڪثريت باڊي فونٽس جي آھي. سنڌي ٻوليءَ جي ڪمپيوٽر تي لکت کي 29 سال ٿيا آھن، ھنن عرصي ۾ ڪيترائي ڪتاب ڇاپيا ويا آھن پر انھن جون سافٽ ڪاپيون موجود ناھن، تنھنڪري بوقت ضرورت انھن ڪتابن کي OCR وسيلي ٻيھر سافٽ ۾ تبديل ڪرڻو پوندو تہ جيئن اسين، انھن جا اِي ايڊيشن ڏئي قومي ورثي کي خضري عمر ڏئي سگهون، انھيءَ سلسلي ۾ ئي ھن وقت ھڪ فونٽ ”ايم بي لطيفي“ جي OCR جوڙي شروعات ڪئي وئي آھي، جيڪو سڀني فونٽن جي ماءُ آھي. ھن وقت ھي فونٽ 387 گلفس تي مشتمل آھي، جنھن ۾ انگريزي اکرن، انگن، نشانين جا 147 گلف جڏھن تہ 240 گلف رڳو سنڌي ٻوليءَ جا آھن. ھن کي ھينئن سمجهو تہ اکرن جون جدا جدا شڪليون ٿينديون آھن جيئن ب جي عام شڪل آھي ’ب‘ شروعاتي شڪل اٿس ’بـ‘ وچين ’ـبـ‘ ۽ پڇاڙيءَ واري ’ـب‘ يا لام جي ( ل لـ، ـلـ، ـل) ھاڻي فونٽ ۾ انھن مڙني شڪلين کي جدا جدا طريقن سان استعمال جو طريقو اڳئي ڪمپيوٽر کي سيکاريل ھوندو آھي، تنھنڪري ڪمپيوٽر ڏسيل شڪل کڻي ڪمپوزر جي آرڊر موجب لفظ ٺاھيندو/لکندو ويندو آھي.
او سي آر ۾ عام فونٽ، ان جو وولٽ پروجيڪٽ، SVG فارميٽ ۽ فونٽ جي 3 پاسائين خصوصيتن وارا فائل درڪار ھوندا آھن. او سي آر OCR جيتري منفرد جملن، گھڻي کان گهڻو استعمال ۾ ايندڙ لفظن، ڊڪشنرين، اسپيل چيڪر، اعرابن اکرن جي لگيچرز (اللہ، ﷴ، لا) ۾ پاڻڀري ٿيندي ويندي، اوتري اسانکي اسڪين ڪيل اکرن جي تصويرن مان اکري مٽاسٽا جي نتيجن ۾ پرفيڪشن ملندي. ان سلسلي ۾ پاڻڀرائيءَ کانپوءِ OCR ۾ ھڪ ھڪ ڪري وڌيڪ فونٽن کي شامل ڪيو ويندو. ھن ڏس ۾ بلاڪن وارن فونٽن جوڙڻ جي پڻ ضرورت آھي، جيڪي ڪمپيوٽري ڇپائيءَ کان اڳ پريسن ۾ ڪتب ايندا ھئا، نہ رڳي اھو پر ان کان اڳ ھٿ اکري لکت وارا فونٽ پڻ جوڙڻا پوندا تہ جيئن اسان انھن کي بہ OCR ۾ شامل ڪري پنھنجو قديم تاريخي ورثو ڊجيٽائيز ڪري سگهون.
مان اھڙن مڙني فونٽن جوڙڻ جي امرفياض سان حامي ڀري آھي، رب گهريو تہ جلد اسان پنھنجي ٻوليءَ جي انھن ضرورتن جو پورائو ڪري وٺنداسين.
”سنڌي ٻولي، منھنجي ٻولي“