ڪافي مهينن کان مون ۽ سائين ذيشان رشيد سميت کوڙ ماڻهن کي زين فورو جي 2.0 ورزين جو انتظار هُيو، جنهنجو ڊيمو لنڪ تازو زين فورو وارن رليز ڪيو آهي پر اڃا تائين سافٽويئر رليز نه ڪيو اٿن.
زين فورو سافٽويئر جيترو استعمال ۾ آسان آهي اوترو ئي سرچ انجڻ سان مطابقت رکندڙ پڻ آهي. هن وقت سنڌسلامت فورم زين فورو جي موجوده ورزين 1.4.7 تي هلي رهيو آهي... سائين رشيد سان جڏهن به ڪچهري ٿيندي آهي ته فورم اپڊيٽ جو ذڪر نڪرندو آهي ۽ سائين جو اهو جواب هوندو آهي ته 2.0 ورزين اچي ته يڪو اپڊيٽ ڪنداسين...
بس دل جي ڌڙڪن وڌندي ٿي وڃي ته ڪڏهن ٿي ڪمپني 2.0 کي رليز ڪري ته جيئن سنڌسلامت فورم فيسبوڪ جيان خوبصورت ۽ آسان ڪري سگهجي.
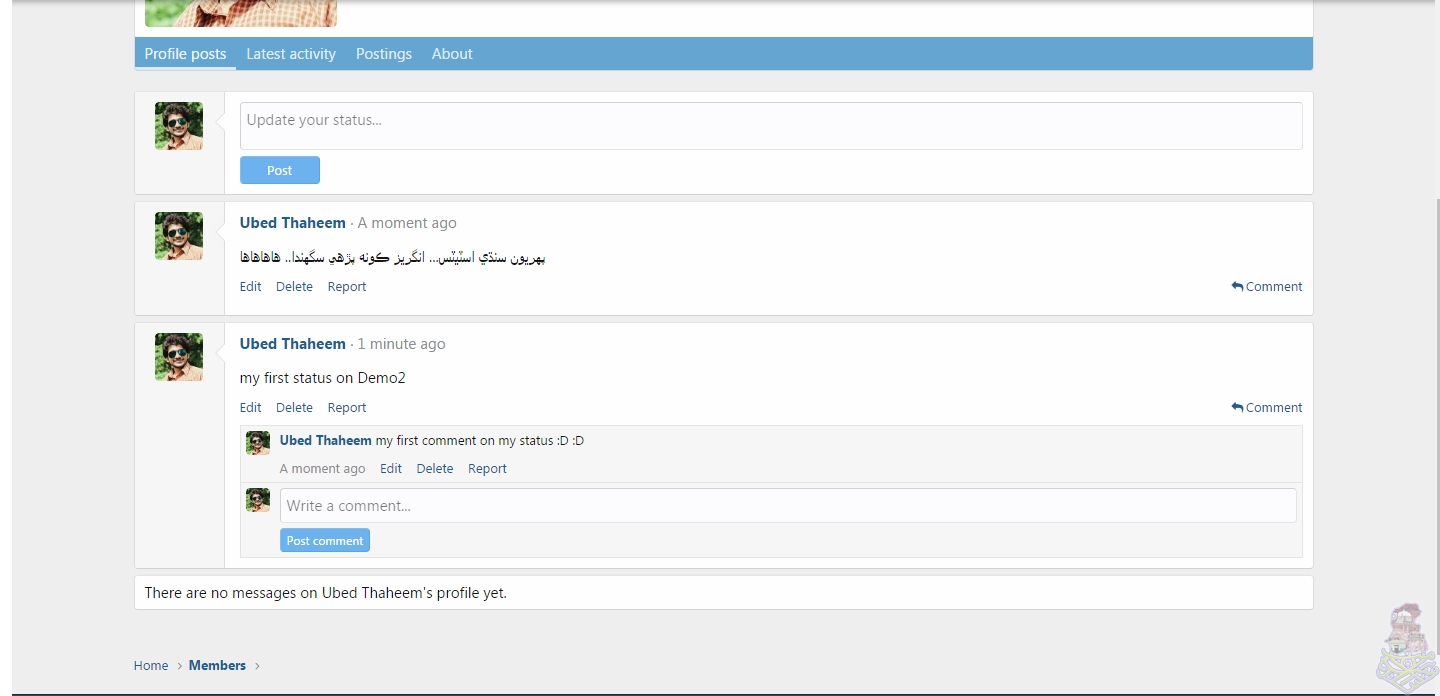
زين فورو جي 2.0 ورزين ۾ يوزر پروفائل ۽ اسٽيٽس ڪُجهه هيئن هوندا...

ان کان علاوه جيڪڏهن توهانجي انگريزي سُٺي آهي ته هِي پڙھي وٺو، زين فورو ۾ ڇا ڇا نئون هوندو.
*******************
Our original what's new in XenForo 2 thread focused on changes that will be visible to end users and administrators. While it did include some references to more developer-oriented changes, we thought that it was time we had a separate thread focusing on what's new for developers.
If you haven't read it, it's worth having a read over some parts of our previous development updates as they talk about some of the development-related changes.
So, in no particular order...
Entities and finders
Entities are XF2's version of data writers. However, they're much more extensive, as:
They are used for reads and writes. Most work you do with data will be through an entity.
They automatically handle encoding and decoding of values. For example, if you define a column as JSON, you just give it the original data structure (probably an array) and it will encode on save. Similarly, when the record is fetched, the value will be decoded back to that array when you access it.
They can have getters to wrap logic around grabbing a value that isn't necessarily stored in the DB. For example, option titles are actually phrases, so there's no title column in the option table. However, we can call $option->title or $option['title'] and it will return a phrase object.
They define their relations and they can be dynamically loaded as needed. $post->Thread->Forum will return the forum that the post belongs to, regardless of whether you included the thread and/or forum records when you loaded the post.
They support some amount of horizontal reuse through the "behavior" system. This currently only adds extra behaviors when write actions are taken, but examples are to automatically adjust likes when content is deleted or hidden and applying change logging to an entity.
Other methods can be added to expose whatever other functionality you need. Call $user->authenticate($password) to see if the password is correct or $thread->canView() to determine if the current visitor can view the thread.
Finders are essentially query builders. In the generic case, they provide methods such as where or order that allow you to apply conditions, ordering and the like based on the DB structure of an entity. However, they can also expose entity-specific methods to provide more complex functionality. Here's an example:
PHP:
$finder = \XF::finder('XF:Thread');
$finder->where('node_id', $nodeId)
->with(['Forum', 'FirstPost'])
->unreadOnly()
->order('last_post_date', 'desc')
->limitByPage($page, $perPage);
$threads = $finder->fetch();
Most of these are generic finder methods, but unreadOnly() is a thread-specific method that applies logic based on the current visitor and complex conditions to limit the results to only unread threads. While XF1 had some similar concepts (implemented very differently), the complex restrictions weren't generally re-usable and that cause a lot of repeated code. In XF2, these constraints are generally shared by the finder object and can be reused. As an example, it's trivial to display only threads that the user has posted in but are also unread.
There's a lot more to this topic. It's a major change to the fundamental data access layer of XenForo and is probably one of the most important concepts to grasp in XF2. As we have other things to cover, let's just add a couple bullet points:
When fetching multiple entities, a collection object is returned rather than a bare array. You can get the array if you like, but the collection object has various helper methods (pluck, filter, groupBy, etc).
Relationships in entities can return many entities. To take a specific example, a thread may be watched by many people, but we generally only care about one person at a time. $thread->Watch[$userId] will return the watch record for the specified $userId. It won't eager load all of the other watchers. The "Watch" value is a "sparse" collection of entities that loads individual records on demand (or you can tell it to fetch all of them).
You can eager load a single record of a "to many" relationship: $finder->with("Watch|$userId").
Finders can be built in any order. You can apply a condition after you set the order or limits.
You don't need to manually create a finder in every case. We have common methods in "repository" objects that setup finders for base/common cases. These repositories can also hold other logic/actions relating to a type of entity. Some examples include methods like countUnreadThreadsInForum(\) or rebuildThreadUserPostCounters(). While these aren't meant to be a generic dumping group, they can also be used for various helper methods, particularly when they manipulate the database directly or don't relate to a single entity.
Most of our finder-related repository methods return the finder rather than the results. This means that they can be manipulated for specific cases or extended to add extra behaviors. For example, findThreadsForForumView() could be extended to always include a specific relation (though there is another place this could be done within the thread finder).
Ok I lied, that was more than a couple.")
Service oriented system
Most complex actions have now been moved to service objects that represent that action only. Most services work in a "setup and go" type of approach; you setup your configuration and then call a method to complete the action.
This example was posted in the development update, but it's a good example:
PHP:
/** @var \XF\Service\Thread\Mover $mover */
$mover = $this->app()->service('XF:Thread\Mover', $thread);
if ($options['alert'])
{
$mover->setSendAlert(true, $options['alert_reason']);
}
if ($options['notify_watchers'])
{
$mover->setNotifyWatchers();
}
if ($options['redirect'])
{
$mover->setRedirect(true, $options['redirect_length']);
}
if ($options['prefix_id'] !== null)
{
$mover->setPrefix($options['prefix_id']);
}
$mover->move($targetForum);
This is roughly the sort of code you'd see in the controller. $options would be based on the user input. The actual code for doing the changes is done within the thread move service. This includes actually moving the thread and changing the thread prefix, creating a redirect, notifying the watchers, sending the alert and logging the action. Any other location wanting to move a thread can call this service with the desired configuration and go; there's no duplication of "business logic".
Now this example is a little simplified for the sake of keeping it focused on the service. However, what you'll actually find is that most service calls in XF2 create and configure the service in one method and then pass the service to another method to actually carry out the action. This is what's actually in the move method of the thread controller:
PHP:
$this->setupThreadMove($thread, $targetForum)->move($targetForum);
Because the services do all of the setup in the setupThreadMove method, this creates a perfect hook/injection point for custom behavior. Add your custom options to the service and then configure them by extending the setupThreadMove method. No creating hacky global variables/registry keys to try to inject your additional changes.
Form actions
Speaking of avoiding hacky global variables and registry keys to do extensions...
Not all actions use services. A lot of the admin control panel pages fit in the CRUD model: create, read, update, delete. They just take user input, pass it to the entity and save it. They don't try to manipulate the user input in any way or trigger other actions.
Instead of creating a service for every single case, we use a FormAction object that allows us to mimic the "setup and go" behavior of services. These actions break down into several phases: setup, validate, apply, complete. Behaviors can be added to each one and when ready, we "run" the action. If any errors occur during validation, they're thrown and apply never runs.
The simplest case would be something like how we save a style:
PHP:
$form = $this->formAction();
$input = $this->filter([
'parent_id' => 'uint',
'title' => 'str',
'description' => 'str',
'user_selectable' => 'bool'
]);
$form->basicEntitySave($style, $input);
basicEntitySave() is a helper method that pushes the input into the entity during setup, validates it through preSave(), and saves it during the apply step.
Like in services, this happens within a method and the form action is returned from it and run:
PHP:
$this->styleSaveProcess($style)->run();
So if you have modified the form to add extra input, you'd just inject that using something like:
PHP:
$form->setup(function() use ($style, $customValue)
{
$style->custom_value = $customValue;
});
Use of LESS (CSS pre-processor) and BEM-styled CSS
We've discussed this in the past so I won't go into too much detail but it's worth mentioning it again.
In general, we're using LESS rather than raw CSS. If you're not familiar with LESS, I recommend checking out the functionality listed on their site to get a better idea of how it works. You'll find it's very similar to CSS, so there isn't a huge learning curve. It provides functionality like various manipulation functions (such as darkening colors) and support for nesting selectors. Significantly, it also provides "mixins" which allow us to easily create functions to encapsulate common CSS patterns.
(Yes, we considered SCSS on multiple occasions. It wasn't a fit for our needs. We won't be changing from LESS.)
Generally speaking, our CSS is structured along the lines of BEM: block, element, modifier. This means our classes are organized along the lines of .block, .block-row, .block-row--minor. If you explore the HTML you see here, it should be much clearer.
Unified template system, templates in the file system
There is now only one template system to power public-facing, admin and email templates. They are separated by type, but otherwise they are identical. This means:
The same template syntax is available everywhere (though you wouldn't want to use most complex features in email templates).
You can include a template of a different type from the current template by prefixing the type (public:thread_view).
The same editing system is used for each type of template, so functionality is shared (includes history, merging and template modifications, for example).
This means that email templates are now customizable. The email will be build using the site's default style. Email components now come from specific parts within the rendered template base on tags like <mail:subject>. We also automatically inline any CSS in emails to improve display in various clients.
Finally, all templates are now always served from the file system. This means that they will benefit from opcode caching.
Extended template syntax
While the template syntax is fairly similar to XF1, XF2's functionality is expanded. Let's look at an example from a user's profile:
HTML:
<xf:if is="$user.canPostOnProfile()">
<xf:set var="$firstProfilePost" value="{$profilePosts|first}" />
<xf:macro template="profile_post_macros" name="submit"
arg-user="{$user}"
arg-lastDate="{{ $firstProfilePost.post_date ?: 0 }}"
/>
</xf:if>
<xf:if is="$profilePosts is not empty">
<xf:foreach loop="$profilePosts" value="$profilePost">
<xf:macro template="profile_post_macros"
name="{{ $profilePost.message_state == 'deleted' ? 'profile_post_deleted' : 'profile_post' }}"
arg-profilePost="{$profilePost}"
/>
</xf:foreach>
<xf:else />
<div class="block-row">{{ phrase('there_no_messages_on_xs_profile_yet', {'name': $user.username}) }}</div>
</xf:if>
Things to note:
You can call (some) methods on entities in templates. They must have a whitelisted prefix (that implies the method does not change data).
{$profilePosts|first} is using a filter to pull out just the first value from the collection/array. Filters are roughly another syntax around manipulating the first parameter. They can be chained and take arguments though: {$value|replace('from', 'to')|to_upper}
Conditions can be "is" and "is not". These are known as tests. Currently only empty is exposed but this may be expanded. These tests can wrap complex logic in an easy to understand way. (The "empty" test is true if the value is an empty string, false, null or empty array; or if the value is a countable object with a count of 0; or if the value is an object with __toString that evaluates to an empty string.)
Complex expressions are triggered with {{ ... }}. You can see calls to templater functions here (phrase), the use of the ternary operator, and the creation of name-value pairs like in JavaScript with curly braces. Other operators (such as math and concatenation) are available and non-string values such as true, false and null can be represented as such.
The big one thing here are the calls to macros.
Macros are similar to template includes, but they take particular arguments. It is much easier to see what options are available for a given macro and the macro variables don't pollute the scope of the calling template. The profile post macro is defined as:
HTML:
<xf:macro name="profile_post"
arg-profilePost="!"
arg-showTargetUser="{{ false }}"
arg-allowInlineMod="{{ true }}"
>
It defines all of the available arguments, which become available within the body of the macro as {$profilePost}, {$showTargetUser}, {$allowInlineMod}. The value of the macro arguments is their default value if not provided; the "!" indicates that it's a required argument and will error if not provided.
Again, there's a lot more to this can than be covered in this overview.
New routing system
In XF1, custom PHP code had to be written to match and generate most URLs. In XF2, we use a custom syntax to allow us to do both automatically in most cases.
Threads are a simple example. The "threads" route prefix is entered and the following is given as the "route format":
Code:
:int<thread_id,title>/ age
age
(Because of the route prefix, this is effectively matching threads/:int<thread_id,title>/age.)
The :int<thread_id,title> indicates that it's an integer-based parameter. For building an outgoing link, we pull the integer from the thread_id key of the data passed in. If a title key is passed into the data, it will be "slugified" and prepended to the integer ID like you see in the URL to this page. For matching an incoming URL, this gets turned into a regular expression that matches the integer parameter format.
age is a shortcut for generating the page-123 part of a link. In this case, it looks for the page in the link parameters. If found, it's put in the URL and then removed from the params. For incoming parsing, if matched (it can be empty), it will add the page number to the parameters passed to a controller.
When a link is built in template, it's done through a call like this: {{ link('members/following', $user, {'page': 3}) }} I'm using this particular example because of the "following" part. Normally, this will be the action; the link will be built with the basic "members" match. However, if there's a route that matches the prefix "members" and the "sub-name" following, it will be used instead. This is true here, so it builds a link like the following:
Code:
members/:int<user_id,username>/following/age
For incoming route matching, this route will be tested before the basic members route; if it matches, it will be used.
This sub-name system allows behavior changes (such as moving where the page param would normally go in this example) or sub-grouping (such as used in things like the resource manager and add-ons).
As with the other systems discussed today, there are a lot more options available to the routing system.
Content type management
Content type handlers are now managed through the control panel and will be included as part of add-ons. No more manual management.
To account for this, content types themselves are not attached to add-ons. Only the specific handlers. This avoids certain bugs and issues that happened in XF1.
Most content type handlers are fairly similar to what you'd find in XF1. For example, attachment_handler_class would map to XF\Attachment\Post for posts. There are some new ones though, including:
entity, which maps a content type to an entity (and therefore to a finder and repository)
phrase, which maps a content type to a phrase name (singular version)
phrase_plural, which maps a content type to a phrase name (plural version)
...and other handler class systems which may not have existed in XF1
This is far from everything. There's too much to cover in one day, s we'll be back later with more details.
زين فورو سافٽويئر جيترو استعمال ۾ آسان آهي اوترو ئي سرچ انجڻ سان مطابقت رکندڙ پڻ آهي. هن وقت سنڌسلامت فورم زين فورو جي موجوده ورزين 1.4.7 تي هلي رهيو آهي... سائين رشيد سان جڏهن به ڪچهري ٿيندي آهي ته فورم اپڊيٽ جو ذڪر نڪرندو آهي ۽ سائين جو اهو جواب هوندو آهي ته 2.0 ورزين اچي ته يڪو اپڊيٽ ڪنداسين...
بس دل جي ڌڙڪن وڌندي ٿي وڃي ته ڪڏهن ٿي ڪمپني 2.0 کي رليز ڪري ته جيئن سنڌسلامت فورم فيسبوڪ جيان خوبصورت ۽ آسان ڪري سگهجي.
زين فورو جي 2.0 ورزين ۾ يوزر پروفائل ۽ اسٽيٽس ڪُجهه هيئن هوندا...
ان کان علاوه جيڪڏهن توهانجي انگريزي سُٺي آهي ته هِي پڙھي وٺو، زين فورو ۾ ڇا ڇا نئون هوندو.
*******************
Our original what's new in XenForo 2 thread focused on changes that will be visible to end users and administrators. While it did include some references to more developer-oriented changes, we thought that it was time we had a separate thread focusing on what's new for developers.
If you haven't read it, it's worth having a read over some parts of our previous development updates as they talk about some of the development-related changes.
So, in no particular order...
Entities and finders
Entities are XF2's version of data writers. However, they're much more extensive, as:
They are used for reads and writes. Most work you do with data will be through an entity.
They automatically handle encoding and decoding of values. For example, if you define a column as JSON, you just give it the original data structure (probably an array) and it will encode on save. Similarly, when the record is fetched, the value will be decoded back to that array when you access it.
They can have getters to wrap logic around grabbing a value that isn't necessarily stored in the DB. For example, option titles are actually phrases, so there's no title column in the option table. However, we can call $option->title or $option['title'] and it will return a phrase object.
They define their relations and they can be dynamically loaded as needed. $post->Thread->Forum will return the forum that the post belongs to, regardless of whether you included the thread and/or forum records when you loaded the post.
They support some amount of horizontal reuse through the "behavior" system. This currently only adds extra behaviors when write actions are taken, but examples are to automatically adjust likes when content is deleted or hidden and applying change logging to an entity.
Other methods can be added to expose whatever other functionality you need. Call $user->authenticate($password) to see if the password is correct or $thread->canView() to determine if the current visitor can view the thread.
Finders are essentially query builders. In the generic case, they provide methods such as where or order that allow you to apply conditions, ordering and the like based on the DB structure of an entity. However, they can also expose entity-specific methods to provide more complex functionality. Here's an example:
PHP:
$finder = \XF::finder('XF:Thread');
$finder->where('node_id', $nodeId)
->with(['Forum', 'FirstPost'])
->unreadOnly()
->order('last_post_date', 'desc')
->limitByPage($page, $perPage);
$threads = $finder->fetch();
Most of these are generic finder methods, but unreadOnly() is a thread-specific method that applies logic based on the current visitor and complex conditions to limit the results to only unread threads. While XF1 had some similar concepts (implemented very differently), the complex restrictions weren't generally re-usable and that cause a lot of repeated code. In XF2, these constraints are generally shared by the finder object and can be reused. As an example, it's trivial to display only threads that the user has posted in but are also unread.
There's a lot more to this topic. It's a major change to the fundamental data access layer of XenForo and is probably one of the most important concepts to grasp in XF2. As we have other things to cover, let's just add a couple bullet points:
When fetching multiple entities, a collection object is returned rather than a bare array. You can get the array if you like, but the collection object has various helper methods (pluck, filter, groupBy, etc).
Relationships in entities can return many entities. To take a specific example, a thread may be watched by many people, but we generally only care about one person at a time. $thread->Watch[$userId] will return the watch record for the specified $userId. It won't eager load all of the other watchers. The "Watch" value is a "sparse" collection of entities that loads individual records on demand (or you can tell it to fetch all of them).
You can eager load a single record of a "to many" relationship: $finder->with("Watch|$userId").
Finders can be built in any order. You can apply a condition after you set the order or limits.
You don't need to manually create a finder in every case. We have common methods in "repository" objects that setup finders for base/common cases. These repositories can also hold other logic/actions relating to a type of entity. Some examples include methods like countUnreadThreadsInForum(\) or rebuildThreadUserPostCounters(). While these aren't meant to be a generic dumping group, they can also be used for various helper methods, particularly when they manipulate the database directly or don't relate to a single entity.
Most of our finder-related repository methods return the finder rather than the results. This means that they can be manipulated for specific cases or extended to add extra behaviors. For example, findThreadsForForumView() could be extended to always include a specific relation (though there is another place this could be done within the thread finder).
Ok I lied, that was more than a couple.
Service oriented system
Most complex actions have now been moved to service objects that represent that action only. Most services work in a "setup and go" type of approach; you setup your configuration and then call a method to complete the action.
This example was posted in the development update, but it's a good example:
PHP:
/** @var \XF\Service\Thread\Mover $mover */
$mover = $this->app()->service('XF:Thread\Mover', $thread);
if ($options['alert'])
{
$mover->setSendAlert(true, $options['alert_reason']);
}
if ($options['notify_watchers'])
{
$mover->setNotifyWatchers();
}
if ($options['redirect'])
{
$mover->setRedirect(true, $options['redirect_length']);
}
if ($options['prefix_id'] !== null)
{
$mover->setPrefix($options['prefix_id']);
}
$mover->move($targetForum);
This is roughly the sort of code you'd see in the controller. $options would be based on the user input. The actual code for doing the changes is done within the thread move service. This includes actually moving the thread and changing the thread prefix, creating a redirect, notifying the watchers, sending the alert and logging the action. Any other location wanting to move a thread can call this service with the desired configuration and go; there's no duplication of "business logic".
Now this example is a little simplified for the sake of keeping it focused on the service. However, what you'll actually find is that most service calls in XF2 create and configure the service in one method and then pass the service to another method to actually carry out the action. This is what's actually in the move method of the thread controller:
PHP:
$this->setupThreadMove($thread, $targetForum)->move($targetForum);
Because the services do all of the setup in the setupThreadMove method, this creates a perfect hook/injection point for custom behavior. Add your custom options to the service and then configure them by extending the setupThreadMove method. No creating hacky global variables/registry keys to try to inject your additional changes.
Form actions
Speaking of avoiding hacky global variables and registry keys to do extensions...
Not all actions use services. A lot of the admin control panel pages fit in the CRUD model: create, read, update, delete. They just take user input, pass it to the entity and save it. They don't try to manipulate the user input in any way or trigger other actions.
Instead of creating a service for every single case, we use a FormAction object that allows us to mimic the "setup and go" behavior of services. These actions break down into several phases: setup, validate, apply, complete. Behaviors can be added to each one and when ready, we "run" the action. If any errors occur during validation, they're thrown and apply never runs.
The simplest case would be something like how we save a style:
PHP:
$form = $this->formAction();
$input = $this->filter([
'parent_id' => 'uint',
'title' => 'str',
'description' => 'str',
'user_selectable' => 'bool'
]);
$form->basicEntitySave($style, $input);
basicEntitySave() is a helper method that pushes the input into the entity during setup, validates it through preSave(), and saves it during the apply step.
Like in services, this happens within a method and the form action is returned from it and run:
PHP:
$this->styleSaveProcess($style)->run();
So if you have modified the form to add extra input, you'd just inject that using something like:
PHP:
$form->setup(function() use ($style, $customValue)
{
$style->custom_value = $customValue;
});
Use of LESS (CSS pre-processor) and BEM-styled CSS
We've discussed this in the past so I won't go into too much detail but it's worth mentioning it again.
In general, we're using LESS rather than raw CSS. If you're not familiar with LESS, I recommend checking out the functionality listed on their site to get a better idea of how it works. You'll find it's very similar to CSS, so there isn't a huge learning curve. It provides functionality like various manipulation functions (such as darkening colors) and support for nesting selectors. Significantly, it also provides "mixins" which allow us to easily create functions to encapsulate common CSS patterns.
(Yes, we considered SCSS on multiple occasions. It wasn't a fit for our needs. We won't be changing from LESS.)
Generally speaking, our CSS is structured along the lines of BEM: block, element, modifier. This means our classes are organized along the lines of .block, .block-row, .block-row--minor. If you explore the HTML you see here, it should be much clearer.
Unified template system, templates in the file system
There is now only one template system to power public-facing, admin and email templates. They are separated by type, but otherwise they are identical. This means:
The same template syntax is available everywhere (though you wouldn't want to use most complex features in email templates).
You can include a template of a different type from the current template by prefixing the type (public:thread_view).
The same editing system is used for each type of template, so functionality is shared (includes history, merging and template modifications, for example).
This means that email templates are now customizable. The email will be build using the site's default style. Email components now come from specific parts within the rendered template base on tags like <mail:subject>. We also automatically inline any CSS in emails to improve display in various clients.
Finally, all templates are now always served from the file system. This means that they will benefit from opcode caching.
Extended template syntax
While the template syntax is fairly similar to XF1, XF2's functionality is expanded. Let's look at an example from a user's profile:
HTML:
<xf:if is="$user.canPostOnProfile()">
<xf:set var="$firstProfilePost" value="{$profilePosts|first}" />
<xf:macro template="profile_post_macros" name="submit"
arg-user="{$user}"
arg-lastDate="{{ $firstProfilePost.post_date ?: 0 }}"
/>
</xf:if>
<xf:if is="$profilePosts is not empty">
<xf:foreach loop="$profilePosts" value="$profilePost">
<xf:macro template="profile_post_macros"
name="{{ $profilePost.message_state == 'deleted' ? 'profile_post_deleted' : 'profile_post' }}"
arg-profilePost="{$profilePost}"
/>
</xf:foreach>
<xf:else />
<div class="block-row">{{ phrase('there_no_messages_on_xs_profile_yet', {'name': $user.username}) }}</div>
</xf:if>
Things to note:
You can call (some) methods on entities in templates. They must have a whitelisted prefix (that implies the method does not change data).
{$profilePosts|first} is using a filter to pull out just the first value from the collection/array. Filters are roughly another syntax around manipulating the first parameter. They can be chained and take arguments though: {$value|replace('from', 'to')|to_upper}
Conditions can be "is" and "is not". These are known as tests. Currently only empty is exposed but this may be expanded. These tests can wrap complex logic in an easy to understand way. (The "empty" test is true if the value is an empty string, false, null or empty array; or if the value is a countable object with a count of 0; or if the value is an object with __toString that evaluates to an empty string.)
Complex expressions are triggered with {{ ... }}. You can see calls to templater functions here (phrase), the use of the ternary operator, and the creation of name-value pairs like in JavaScript with curly braces. Other operators (such as math and concatenation) are available and non-string values such as true, false and null can be represented as such.
The big one thing here are the calls to macros.
Macros are similar to template includes, but they take particular arguments. It is much easier to see what options are available for a given macro and the macro variables don't pollute the scope of the calling template. The profile post macro is defined as:
HTML:
<xf:macro name="profile_post"
arg-profilePost="!"
arg-showTargetUser="{{ false }}"
arg-allowInlineMod="{{ true }}"
>
It defines all of the available arguments, which become available within the body of the macro as {$profilePost}, {$showTargetUser}, {$allowInlineMod}. The value of the macro arguments is their default value if not provided; the "!" indicates that it's a required argument and will error if not provided.
Again, there's a lot more to this can than be covered in this overview.
New routing system
In XF1, custom PHP code had to be written to match and generate most URLs. In XF2, we use a custom syntax to allow us to do both automatically in most cases.
Threads are a simple example. The "threads" route prefix is entered and the following is given as the "route format":
Code:
:int<thread_id,title>/
age(Because of the route prefix, this is effectively matching threads/:int<thread_id,title>/
age.)The :int<thread_id,title> indicates that it's an integer-based parameter. For building an outgoing link, we pull the integer from the thread_id key of the data passed in. If a title key is passed into the data, it will be "slugified" and prepended to the integer ID like you see in the URL to this page. For matching an incoming URL, this gets turned into a regular expression that matches the integer parameter format.
age is a shortcut for generating the page-123 part of a link. In this case, it looks for the page in the link parameters. If found, it's put in the URL and then removed from the params. For incoming parsing, if matched (it can be empty), it will add the page number to the parameters passed to a controller.When a link is built in template, it's done through a call like this: {{ link('members/following', $user, {'page': 3}) }} I'm using this particular example because of the "following" part. Normally, this will be the action; the link will be built with the basic "members" match. However, if there's a route that matches the prefix "members" and the "sub-name" following, it will be used instead. This is true here, so it builds a link like the following:
Code:
members/:int<user_id,username>/following/
ageFor incoming route matching, this route will be tested before the basic members route; if it matches, it will be used.
This sub-name system allows behavior changes (such as moving where the page param would normally go in this example) or sub-grouping (such as used in things like the resource manager and add-ons).
As with the other systems discussed today, there are a lot more options available to the routing system.
Content type management
Content type handlers are now managed through the control panel and will be included as part of add-ons. No more manual management.
To account for this, content types themselves are not attached to add-ons. Only the specific handlers. This avoids certain bugs and issues that happened in XF1.
Most content type handlers are fairly similar to what you'd find in XF1. For example, attachment_handler_class would map to XF\Attachment\Post for posts. There are some new ones though, including:
entity, which maps a content type to an entity (and therefore to a finder and repository)
phrase, which maps a content type to a phrase name (singular version)
phrase_plural, which maps a content type to a phrase name (plural version)
...and other handler class systems which may not have existed in XF1
This is far from everything. There's too much to cover in one day, s we'll be back later with more details.